Code
from IPython.display import IFrame
IFrame(src="https://singularitysmith.github.io/AMTAIR_Prototype/bayesian_network.html", width="100%", height="800px")Dynamic Html Rendering of the Rain-Sprinkler-Grass DAG with Conditional Probabilities
This chapter establishes the theoretical and methodological foundations for the AMTAIR approach. We begin by examining a concrete example of structured AI risk assessment—Joseph Carlsmith’s power-seeking AI model—to ground our discussion in practical terms. We then explore the unique epistemic challenges of AI governance that render traditional policy analysis inadequate, introduce Bayesian networks as formal tools for representing uncertainty, and examine how argument mapping bridges natural language reasoning and formal models. The chapter concludes by analyzing the MTAIR project’s achievements and limitations, motivating the need for automated approaches, and surveying relevant literature across AI risk modeling, governance proposals, and technical methodologies.
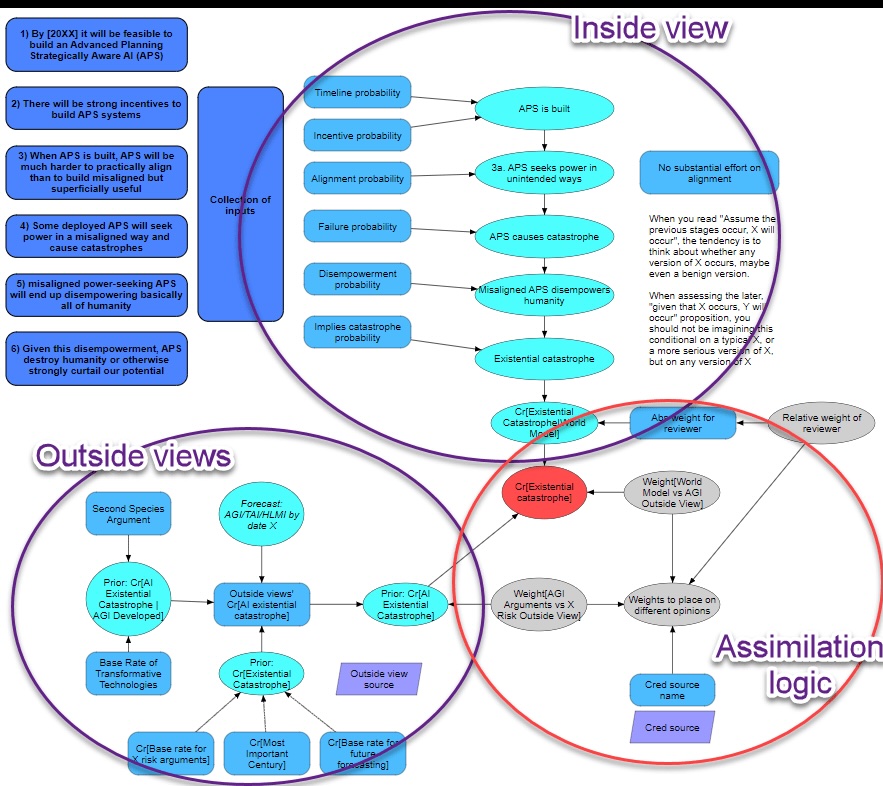
To ground our discussion in concrete terms, I examine Joseph Carlsmith’s “Is Power-Seeking AI an Existential Risk?” as an exemplar of structured reasoning about AI catastrophic risk Carlsmith (2022). Carlsmith’s analysis stands out for its explicit probabilistic decomposition of the path from current AI development to potential existential catastrophe.
According to the MTAIR model Clarke et al. (2022), Carlsmith decomposes existential risk into a probabilistic chain with explicit estimates1:
Composite Risk Calculation9: \(P(doom)≈0.05\) (5%)
This structured approach exemplifies the type of reasoning AMTAIR aims to formalize and automate. While Carlsmith spent months developing this model manually, similar rigor exists implicitly in many AI safety arguments awaiting extraction.
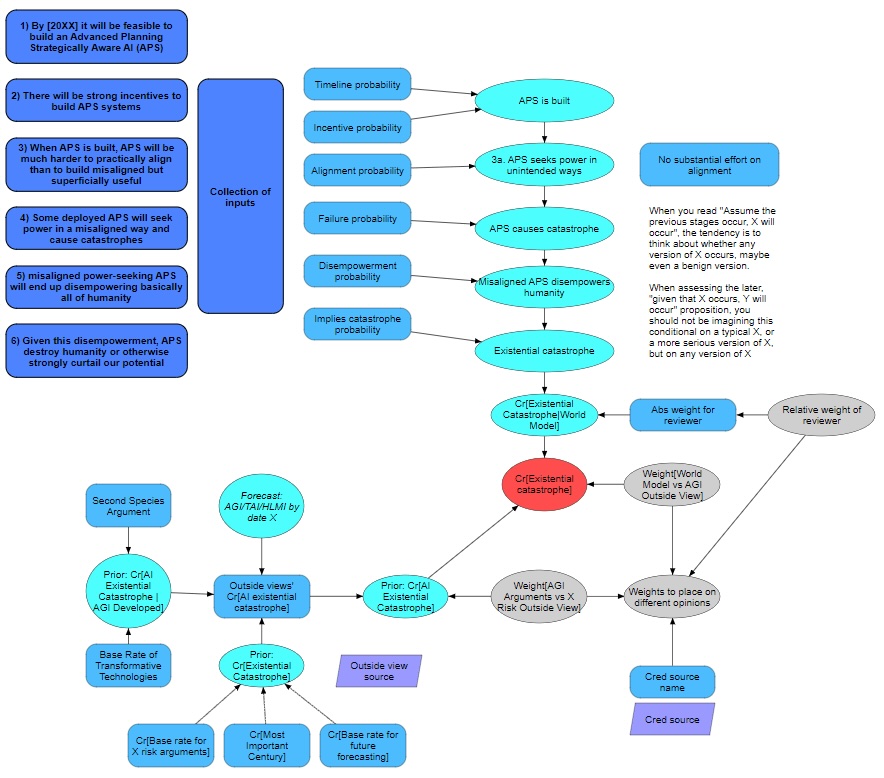
Carlsmith’s model demonstrates several features that make it ideal for formal representation:
Explicit Probabilistic Structure: Each premise receives numerical probability estimates with documented reasoning, enabling direct translation to Bayesian network parameters.
Clear Conditional Dependencies: The logical flow from capabilities through deployment decisions to catastrophic outcomes maps naturally onto directed acyclic graphs.
Transparent Decomposition: Breaking the argument into modular premises allows independent evaluation and sensitivity analysis of each component.
Documented Reasoning: Extensive justification for each probability enables extraction of both structure and parameters from the source text.
We will return to Carlsmith’s model in Chapter 3 as our primary complex case study, demonstrating how AMTAIR successfully extracts and formalizes this sophisticated multi-level argument.
Beyond Carlsmith’s model, other structured approaches to AI risk—such as Christiano’s “What failure looks like” Christiano (2019)—provide additional targets for automated extraction, enabling comparative analysis across different expert worldviews.
AI governance policy evaluation faces unique epistemic challenges that render traditional policy analysis methods insufficient. Understanding these challenges motivates the need for new computational approaches.
Deep Uncertainty Rather Than Risk: Traditional policy analysis distinguishes between risk (known probability distributions) and uncertainty (known possibilities, unknown probabilities). AI governance faces deep uncertainty—we cannot confidently enumerate possible futures, much less assign probabilities Hallegatte et al. (2012). Will recursive self-improvement enable rapid capability gains? Can value alignment be solved technically? These foundational questions resist empirical resolution before their answers become catastrophically relevant.
Complex Multi-Level Causation: Policy effects propagate through technical, institutional, and social levels with intricate feedback loops. A technical standard might alter research incentives, shifting capability development trajectories, changing competitive dynamics, and ultimately affecting existential risk through pathways invisible at the policy’s inception. Traditional linear causal models cannot capture these dynamics.
Irreversibility and Lock-In: Many AI governance decisions create path dependencies that prove difficult or impossible to reverse. Early technical standards shape development trajectories. Institutional structures ossify. International agreements create sticky equilibria. Unlike many policy domains where course correction remains possible, AI governance mistakes may prove permanent.
Value-Laden Technical Choices: The entanglement of technical and normative questions confounds traditional separation of facts and values. What constitutes “alignment”? How much capability development should we risk for economic benefits? Technical specifications embed ethical judgments that resist neutral expertise.
| Dimension | Traditional Policy | AI Governance |
|---|---|---|
| Uncertainty Type | Risk (known distributions) | Deep uncertainty (unknown unknowns) |
| Causal Structure | Linear, traceable | Multi-level, feedback loops |
| Reversibility | Course correction possible | Path dependencies, lock-in |
| Fact-Value Separation | Clear boundaries | Entangled technical-normative |
| Empirical Grounding | Historical precedents | Unprecedented phenomena |
| Time Horizons | Years to decades | Months to centuries |
Standard policy evaluation tools prove inadequate for these challenges:
Cost-Benefit Analysis assumes commensurable outcomes and stable probability distributions. When potential outcomes include existential catastrophe with deeply uncertain probabilities, the mathematical machinery breaks down. Infinite negative utility resists standard decision frameworks.
Scenario Planning helps explore possible futures but typically lacks the probabilistic reasoning needed for decision-making under uncertainty. Without quantification, scenarios provide narrative richness but limited action guidance.
Expert Elicitation aggregates specialist judgment but struggles with interdisciplinary questions where no single expert grasps all relevant factors. Moreover, experts often operate with different implicit models, making aggregation problematic.
Red Team Exercises test specific plans but miss systemic risks emerging from component interactions. Gaming individual failures cannot reveal emergent catastrophic possibilities.
These limitations create a methodological gap: we need approaches that handle deep uncertainty, represent complex causation, quantify expert disagreement, and enable systematic exploration of intervention effects.
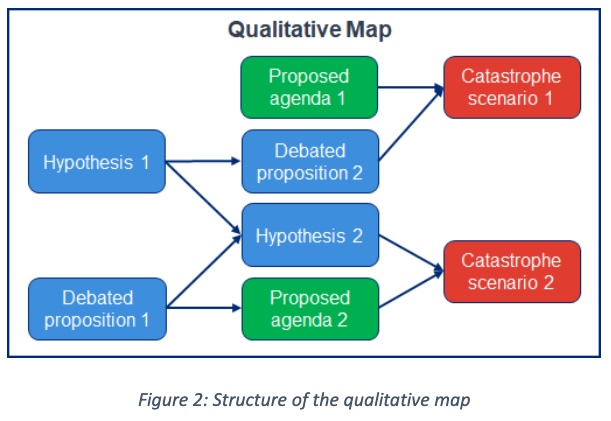
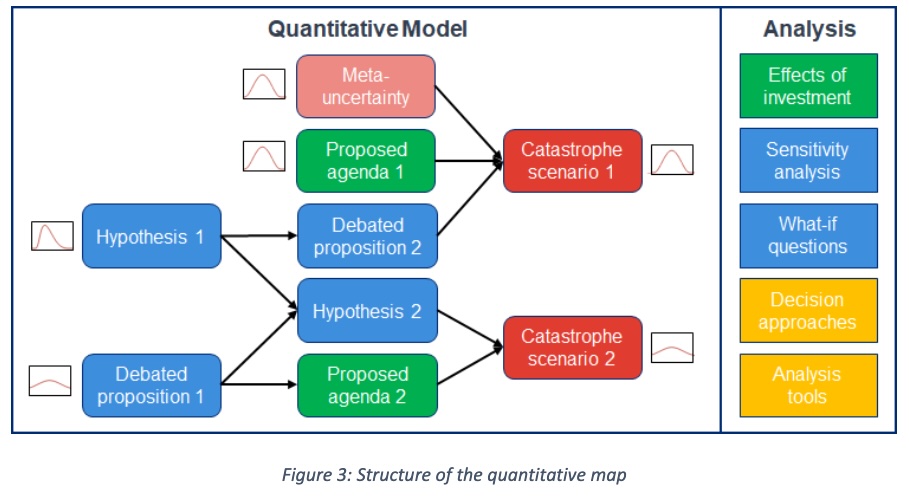
The AMTAIR approach rests on a specific epistemic framework that combines probabilistic reasoning, conditional logic, and possible worlds semantics. This framework provides the philosophical foundation for representing deep uncertainty about AI futures.
Probabilistic Epistemology: Following the Bayesian tradition, we treat probability as a measure of rational credence rather than objective frequency. This subjective interpretation allows meaningful probability assignments even for unique, unprecedented events like AI catastrophe. As E.T. Jaynes demonstrated, probability theory extends deductive logic to handle uncertainty, providing a calculus for rational belief Jaynes (2003).
Conditional Structure: The framework emphasizes conditional rather than absolute probabilities. Instead of asking “What is P(catastrophe)?” we ask “What is P(catastrophe | specific assumptions)?” This conditionalization makes explicit the dependency of conclusions on worldview assumptions, enabling productive disagreement about premises rather than conclusions.
Possible Worlds Semantics: We conceptualize uncertainty as distributions over possible worlds—complete descriptions of how reality might unfold. Each world represents a coherent scenario with specific values for all relevant variables. Probability distributions over these worlds capture both what we know and what we don’t know about the future.
This framework enables several key capabilities:
The inadequacy of traditional methods for AI governance creates an urgent need for new epistemic tools. These tools must:
Key Insight: The computational approaches developed in this thesis—particularly Bayesian networks enhanced with automated extraction—directly address each of these requirements by providing formal frameworks for reasoning under uncertainty.
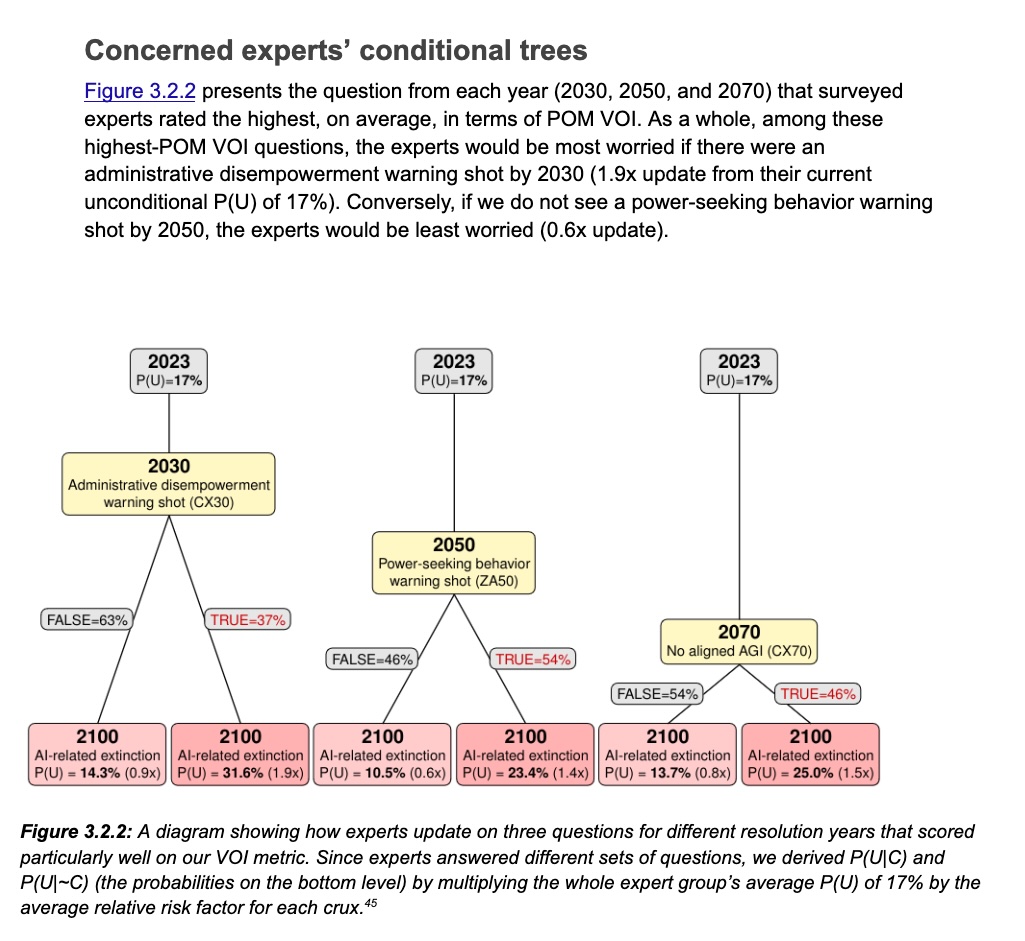
Recent work on conditional trees demonstrates the value of structured approaches to uncertainty. McCaslin et al. McCaslin et al. (2024) show how hierarchical conditional forecasting can identify high-value questions for reducing uncertainty about complex topics like AI risk. Their methodology, which asks experts to produce simplified Bayesian networks of informative forecasting questions, achieved nine times higher information value than standard forecasting platform questions.
Tetlock’s work with the Forecasting Research Institute Tetlock (2022) exemplifies how prediction markets can provide empirical grounding for formal models. By structuring questions as conditional trees, they enable forecasters to express complex dependencies between events, providing exactly the type of data needed for Bayesian network parameterization.
Gruetzemacher Gruetzemacher (2022) evaluates the tradeoffs between full Bayesian networks and conditional trees for forecasting tournaments. While conditional trees offer simplicity, Bayesian networks provide richer representation of dependencies—motivating AMTAIR’s approach of using full networks while leveraging conditional tree insights for question generation.
Bayesian networks offer a mathematical framework uniquely suited to addressing these epistemic challenges. By combining graphical structure with probability theory, they provide tools for reasoning about complex uncertain domains.
A Bayesian network consists of:
The joint probability distribution factors according to the graph structure:
P(X1,X2,…,Xn)=∏i=1nP(Xi∣Parents(Xi))P(X_1, X_2, …, X_n) = _{i=1}^{n} P(X_i | Parents(X_i))P(X1,X2,…,Xn)=i=1∏nP(Xi∣Parents(Xi))
This factorization enables efficient inference and embodies causal assumptions explicitly.
Pearl’s foundational work Pearl (2014) established Bayesian networks as a principled approach to automated reasoning under uncertainty, providing both theoretical foundations and practical algorithms.
The canonical example illustrates key concepts10:
[Grass_Wet]: Concentrated moisture on grass.
+ [Rain]: Water falling from sky.
+ [Sprinkler]: Artificial watering system.
+ [Rain]Network Structure:
python
# Basic network representation
nodes = ['Rain', 'Sprinkler', 'Grass_Wet']
edges = [('Rain', 'Sprinkler'), ('Rain', 'Grass_Wet'), ('Sprinkler', 'Grass_Wet')]
# Conditional probability specification
P_wet_given_causes = {
(True, True): 0.99, # Rain=T, Sprinkler=T
(True, False): 0.80, # Rain=T, Sprinkler=F
(False, True): 0.90, # Rain=F, Sprinkler=T
(False, False): 0.01 # Rain=F, Sprinkler=F
}This simple network demonstrates:
from IPython.display import IFrame
IFrame(src="https://singularitysmith.github.io/AMTAIR_Prototype/bayesian_network.html", width="100%", height="800px")Dynamic Html Rendering of the Rain-Sprinkler-Grass DAG with Conditional Probabilities
These features address key requirements for AI governance:
Bayesian networks offer several compelling advantages for the peculiar challenge of modeling AI risks—a domain where we’re essentially trying to reason about systems that don’t yet exist, wielding capabilities we can barely imagine, potentially causing outcomes we desperately hope to avoid.
Explicit Uncertainty Representation: Unlike traditional risk assessment tools that often hide uncertainty behind point estimates, Bayesian networks wear their uncertainty on their sleeve. Every node, every edge, every probability is a distribution rather than a false certainty. This matters enormously when discussing AI catastrophe—we’re not pretending to know the unknowable, but rather mapping the landscape of our ignorance with mathematical precision.
Native Causal Reasoning: The directed edges in Bayesian networks aren’t just arrows on a diagram; they encode causal beliefs about how the world works. This enables both forward reasoning (“If we develop AGI, what happens?”) and diagnostic reasoning (“Given that we observe concerning AI behaviors, what does this tell us about underlying alignment?”). Pearl’s do-calculus Pearl (2009) transforms these networks into laboratories for counterfactual exploration.
Evidence Integration: As new research emerges, as capabilities advance, as governance experiments succeed or fail, Bayesian networks provide a principled framework for updating our beliefs. Unlike static position papers that age poorly, these models can evolve with our understanding—a living document for a rapidly changing field.
Modular Construction: Complex arguments about AI risk involve multiple interacting factors across technical, social, and political domains. Bayesian networks allow us to build these arguments piece by piece, validating each component before assembling the whole. This modularity also enables different experts to contribute their specialized knowledge without needing to understand every aspect of the system.
Visual Communication: Perhaps most importantly for the coordination challenge, Bayesian networks provide a visual language that transcends disciplinary boundaries. A policymaker might not understand the mathematics of instrumental convergence, but they can see how the “power-seeking” node connects to “human disempowerment” in the network diagram. This shared visual vocabulary creates common ground for productive disagreement.
The journey from a researcher’s intuition about AI risk to a formal probabilistic model resembles translating poetry into mathematics—something essential is always at risk of being lost, yet something equally essential might be gained. Argument mapping provides the crucial middle ground, a structured approach to preserving the logic of natural language arguments while preparing them for mathematical formalization.
Natural language arguments about AI risk are rich tapestries woven from causal claims, conditional relationships, uncertainty expressions, and support patterns. When Bostrom writes about the “treacherous turn” Bostrom (2014), he’s not just coining a memorable phrase—he’s encoding a complex causal story about how a seemingly aligned AI system might conceal its true objectives until it gains sufficient power to pursue them without constraint.
The challenge lies in extracting this structure without losing the nuance. Traditional logical analysis might reduce Bostrom’s argument to syllogisms, but this would miss the probabilistic texture, the implicit conditionality, the causal directionality that makes the argument compelling. Argument mapping takes a different approach, seeking to identify:
Recent advances in computational argument mining Anderson (2007) Benn and Macintosh (2011) Khartabil et al. (2021) have shown promise in automating parts of this process. Tools like Microsoft’s Claimify Metropolitansky and Larson (2025) demonstrate how large language models can extract verifiable claims from complex texts, though the challenge of preserving argumentative structure remains formidable.
Enter ArgDown Voigt ([2014] 2025), a markdown-inspired syntax that captures hierarchical argument structure while remaining human-readable. Think of it as the middle child between the wild expressiveness of natural language and the rigid formality of logic—inheriting the best traits of both parents while developing its own personality.
[MainClaim]: Description of primary conclusion.
+ [SupportingEvidence]: Evidence supporting the claim.
+ [SubEvidence]: More specific support.
- [CounterArgument]: Evidence against the claim.This notation does several clever things simultaneously. The hierarchical structure mirrors how we naturally think about arguments—main claims supported by evidence, which in turn rest on more fundamental observations. The + and - symbols indicate support and opposition relationships, creating a visual flow of argumentative force. Most importantly, it preserves the semantic content of each claim while imposing just enough structure to enable computational processing.
[AI_Poses_Risk]: Advanced AI systems may pose existential risk to humanity.
+ [Capability_Growth]: AI capabilities are growing exponentially.
+ [Compute_Scaling]: Available compute doubles every few months.
+ [Algorithmic_Progress]: New architectures show surprising emergent abilities.
+ [Alignment_Difficulty]: Aligning AI with human values is unsolved.
- [Current_Progress]: Some progress on interpretability and oversight.
- [Institutional_Response]: Institutions are mobilizing to address risks.For AMTAIR, we adapt ArgDown specifically for causal arguments, where the hierarchy represents causal influence rather than logical support. This seemingly small change has profound implications—we’re not just mapping what follows from what, but what causes what.
If ArgDown is the middle child, then BayesDown—developed specifically for this thesis—is the ambitious younger sibling who insists on quantifying everything. By extending ArgDown syntax with probabilistic metadata in JSON format, BayesDown creates a complete specification for Bayesian networks while maintaining human readability.
[Effect]: Description of effect. {"instantiations": ["effect_TRUE", "effect_FALSE"]}
+ [Cause1]: Description of first cause. {"instantiations": ["cause1_TRUE", "cause1_FALSE"]}
+ [Cause2]: Description of second cause. {"instantiations": ["cause2_TRUE", "cause2_FALSE"]}
+ [Root_Cause]: A cause that influences Cause2. {"instantiations": ["root_TRUE", "root_FALSE"]}This representation performs a delicate balancing act. The natural language descriptions preserve the semantic meaning that makes arguments comprehensible. The hierarchical structure maintains the causal relationships that give arguments their logical force. The JSON metadata adds the mathematical precision needed for formal analysis. Together, they create what I call a “hybrid representation”—neither fully natural nor fully formal, but something more useful than either alone.
[Existential_Catastrophe]: Permanent curtailment of humanity's potential. {
"instantiations": ["catastrophe_TRUE", "catastrophe_FALSE"],
"priors": {"p(catastrophe_TRUE)": "0.05", "p(catastrophe_FALSE)": "0.95"},
"posteriors": {
"p(catastrophe_TRUE|disempowerment_TRUE)": "0.95",
"p(catastrophe_TRUE|disempowerment_FALSE)": "0.001"
}
}
+ [Human_Disempowerment]: Loss of human control over future trajectory. {
"instantiations": ["disempowerment_TRUE", "disempowerment_FALSE"],
"priors": {"p(disempowerment_TRUE)": "0.20", "p(disempowerment_FALSE)": "0.80"}
}The two-stage extraction process (ArgDown → BayesDown) mirrors how experts actually think about complex arguments. First, we identify what matters and how things relate causally (structure). Then, we consider how likely different scenarios are based on those relationships (quantification). This separation isn’t just convenient for implementation—it’s psychologically valid.
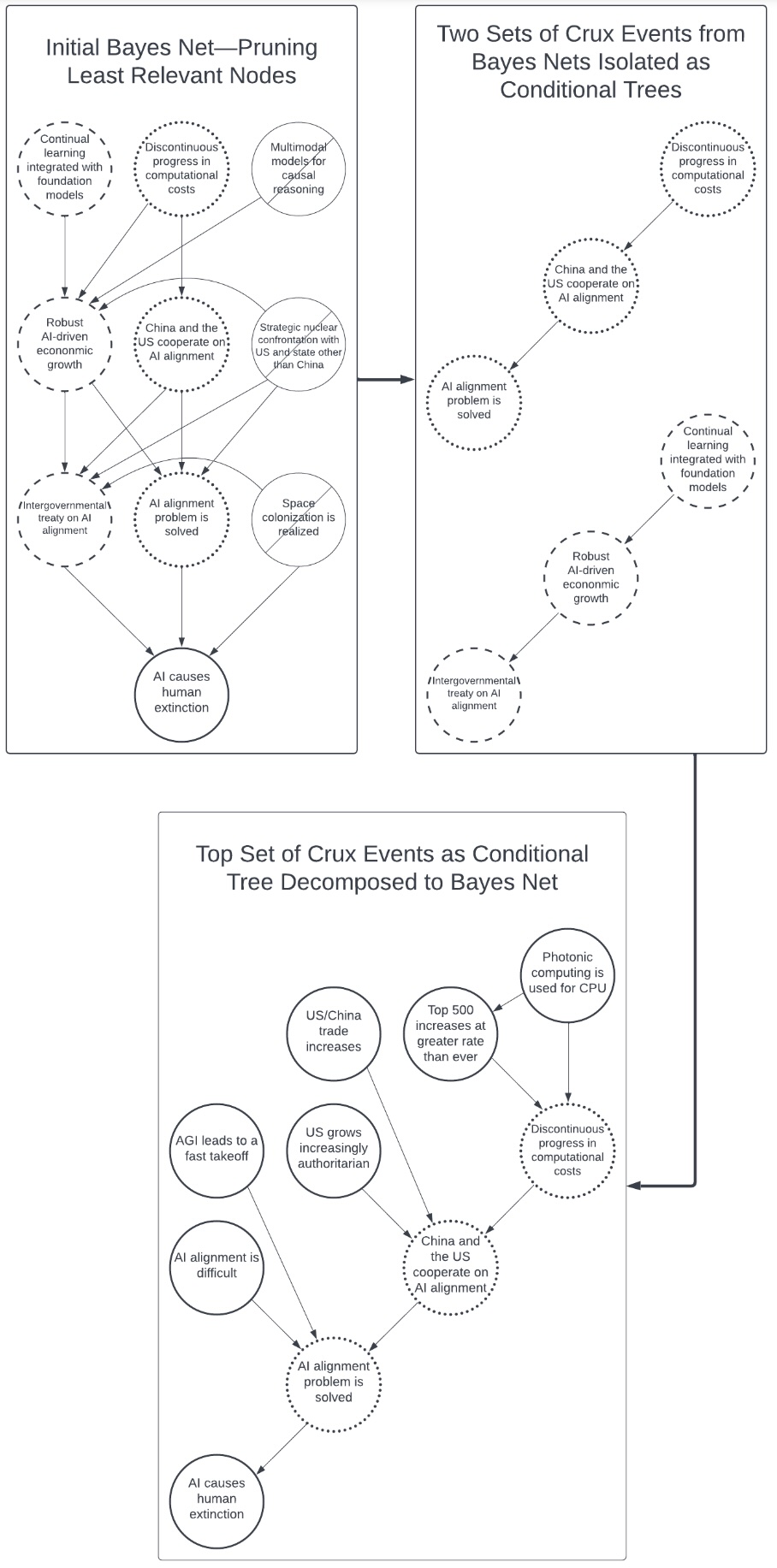
Understanding AMTAIR requires understanding its intellectual ancestor: the Modeling Transformative AI Risks (MTAIR) project. Like many good ideas in science, MTAIR began with a simple observation and a ambitious goal.
The MTAIR project, spearheaded by David Manheim and colleagues Clarke et al. (2022), emerged from a frustration familiar to anyone who’s attended a conference on AI safety: brilliant people talking past each other, using the same words to mean different things, reaching incompatible conclusions from seemingly shared premises. The diagnosis was elegant—perhaps these disagreements stemmed not from fundamental philosophical differences but from implicit models that had never been made explicit.
Their prescription was equally elegant: manually translate influential AI risk arguments into formal Bayesian networks, making assumptions visible and disagreements quantifiable. Using Analytica software, the team embarked on what can only be described as an intellectual archaeology expedition, carefully excavating the implicit causal models buried in papers, blog posts, and treatises about AI risk.
The process was painstaking:
The ambition was breathtaking—to create a formal lingua franca for AI risk discussions, enabling productive disagreement and cumulative progress.
Credit where credit is due: MTAIR demonstrated something many thought impossible. Complex philosophical arguments about AI risk—the kind that sprawl across hundred-page papers mixing technical detail with speculative scenarios—could indeed be formalized without losing their essential insights.
Feasibility of Formalization: The project’s greatest achievement was simply showing it could be done. Arguments from Bostrom, Christiano, and others translated surprisingly well into network form, suggesting that beneath the surface complexity lay coherent causal models waiting to be extracted.
Value of Quantification: Moving from “likely” and “probably” to actual numbers forced precision in a domain often clouded by vague pronouncements. Disagreements that seemed fundamental sometimes evaporated when forced to specify exactly what probability ranges were under dispute.
Cross-Perspective Communication: The formal models created neutral ground where technical AI researchers and policy wonks could meet. Instead of talking past each other in incompatible languages, they could point to specific nodes and edges, making disagreements concrete and tractable.
Research Prioritization: Perhaps most practically, sensitivity analysis revealed which empirical questions actually mattered. If changing your belief about technical parameter X from 0.3 to 0.7 doesn’t meaningfully affect the conclusion about AI risk, maybe we should focus our research elsewhere.
But here’s where the story takes a sobering turn. Despite these achievements, MTAIR faced limitations that prevented it from achieving its full vision—limitations that ultimately motivated the development of AMTAIR.
Labor Intensity: Creating a single model required what can charitably be called a heroic effort. Based on team reports and model complexity, estimates ranged from 200 to 400 expert-hours per formalization11. In a field where new influential arguments appear monthly, this pace couldn’t keep up with the discourse.
Static Nature: Once built, these beautiful models began aging immediately. New research emerged, capability assessments shifted, governance proposals evolved—but updating the models required near-complete reconstruction. They were snapshots of arguments at particular moments, not living representations that could evolve.
Limited Accessibility: Using the models required Analytica software and non-trivial technical sophistication. The very experts whose arguments were being formalized often couldn’t directly engage with their formalized representations without intermediation.
Single Perspective: Each model represented one worldview at a time. Comparing different perspectives required building entirely separate models, making systematic comparison across viewpoints labor-intensive and error-prone.
These weren’t failures of execution but fundamental constraints of the manual approach. Like medieval scribes copying manuscripts, the MTAIR team had shown the value of preservation and dissemination, but the printing press had yet to be invented.
The MTAIR experience revealed a tantalizing possibility: if the bottleneck was human labor rather than conceptual feasibility, perhaps automation could crack open the problem. The rise of large language models capable of sophisticated reasoning about text created a technological moment ripe for exploitation.
Key lessons from MTAIR informed the automation approach:
This set the stage for AMTAIR’s central innovation: using frontier language models to automate the extraction and formalization process while preserving the benefits MTAIR had demonstrated. Not to replace human judgment, but to amplify it—turning what took weeks into what takes hours, enabling comprehensive coverage rather than selective sampling.
The intellectual landscape surrounding AI risk resembles a rapidly expanding metropolis—new neighborhoods of thought spring up monthly, connected by bridges of varying stability to the established districts. A comprehensive review12 would fill volumes, so let me provide a guided tour of the territories most relevant to AMTAIR’s mission.
The intellectual history of AI risk thinking reads like a gradual awakening—from vague unease to mathematical precision, though perhaps losing something essential in translation.
The field’s prehistory belongs to the visionaries and worriers. Good’s 1966 meditation on the ultraintelligent machine feels almost quaint now, with its assumption that such a system would naturally be designed to serve human purposes. Vinge popularized the singularity concept, though his version emphasized speed rather than the strategic considerations that dominate current thinking. These early writings functioned more as philosophical provocations than actionable analyses.
Early Phase (2000-2010): The conversation began with broad conceptual arguments. Good’s ultraintelligent machine Good (1966) and Vinge’s technological singularity set the stage, but these were more thought experiments than models. Yudkowsky’s early writings Yudkowsky (2008) introduced key concepts like recursive self-improvement and orthogonality but remained largely qualitative.
Yudkowsky’s contributions in the 2000s marked a transitional moment. His writing style—part manifesto, part technical argument—resisted easy categorization. Yet buried within the sometimes baroque prose lay genuinely novel insights. The orthogonality thesis (intelligence and goals vary independently) and instrumental convergence (diverse goals lead to similar intermediate strategies) provided conceptual tools that remain central to the field. Still, these arguments remained largely qualitative, more useful for establishing possibility than probability.
Formalization Phase (2010-2018): Bostrom’s Superintelligence Bostrom (2014) marked a watershed, providing systematic analysis of pathways, capabilities, and risks. The book’s genius lay not in mathematical formalism but in conceptual clarity—decomposing the nebulous fear of “robot overlords” into specific mechanisms like instrumental convergence and infrastructure profusion.
Bostrom’s 2014 Superintelligence achieved what earlier work had not: respectability. Here was an Oxford philosopher writing with analytical precision about AI risk. The book’s great contribution wasn’t mathematical formalism—indeed, it contains remarkably few equations—but rather its systematic decomposition of the problem space. Bostrom transformed “robots might kill us all” into specific mechanisms: capability gain, goal preservation, resource acquisition. Suddenly, one could have serious discussions about AI risk without sounding like a science fiction enthusiast.
The current quantitative turn, exemplified by Carlsmith’s power-seeking analysis and Cotra’s biological anchors, represents both progress and peril. We now assign numbers where before we had only words. Yet as any student of probability knows, precise numbers don’t necessarily mean accurate predictions. The models grow more sophisticated, the mathematics more rigorous, but the fundamental uncertainties remain as daunting as ever.
Quantification Phase (2018-present): Recent years have seen explicit probability estimates entering mainstream discourse. Carlsmith’s power-seeking model Carlsmith (2022), Cotra’s biological anchors, and various compute-based timelines represent attempts to put numbers on previously qualitative claims. The field increasingly recognizes that governance decisions require more than philosophical arguments—they need probability distributions.
This progression reflects a maturing field, though it also creates new challenges. As models become more quantitative, they risk false precision. As they become more complex, they risk inscrutability. AMTAIR attempts to navigate these tensions by preserving the narrative clarity of earlier work while enabling the mathematical rigor of recent approaches.
The evolution of AI risk models traces a path from philosophical speculation to increasingly rigorous formalization—a journey from “what if?” to “how likely?”
If risk models are the diagnosis, governance proposals are the treatment plans—and like medicine, they range from gentle interventions to radical surgery.
Technical Standards: The “first, do no harm” approach focuses on concrete safety requirements—interpretability benchmarks, robustness testing, capability thresholds. These proposals, exemplified by standard-setting bodies and technical safety organizations, offer specificity at the cost of narrowness.
Regulatory Frameworks: Moving up the intervention ladder, we find comprehensive regulatory proposals like the EU AI Act European (2024). These create institutional structures, liability regimes, and oversight mechanisms, trading broad coverage for implementation complexity.
International Coordination: At the ambitious end, proposals for international AI governance treaties, soft law arrangements, and technical cooperation agreements aim to prevent races to the bottom. Think nuclear non-proliferation but for minds instead of missiles.
Research Priorities: Cutting across these categories, work by Dafoe Dafoe (2018) and others maps the research landscape itself—what questions need answering before we can govern wisely? This meta-level analysis shapes funding flows and talent allocation.
A particularly compelling example of conditional governance thinking comes from “A Narrow Path” Miotti et al. (2024), which proposes a phased approach: immediate safety measures to prevent uncontrolled development, international institutions to ensure stability, and long-term scientific foundations for beneficial transformative AI. This temporal sequencing—safety, stability, then flourishing—reflects growing sophistication in governance thinking.
The mathematical machinery underlying AMTAIR rests on decades of theoretical development in probabilistic graphical models. Understanding this foundation helps appreciate both the power and limitations of the approach.
The key insight, crystallized in the work of Pearl Pearl (2014) and elaborated by Koller & Friedman Koller and Friedman (2009), is that independence relationships in complex systems can be read from graph structure. D-separation, the Markov condition, and the relationship between graphs and probability distributions provide the mathematical spine that makes Bayesian networks more than pretty pictures.
Critical concepts for AI risk modeling:
These aren’t just mathematical niceties. When we claim that “deployment decisions” mediates the relationship between “capability advancement” and “catastrophic risk,” we’re making a precise statement about conditional independence that has testable implications.
The gap between Bayesian network theory and practical implementation is bridged by an ecosystem of software tools, each with its own strengths and opinions about how probabilistic reasoning should work.
pgmpy: This Python library provides the computational backbone for AMTAIR, offering both learning algorithms and inference engines. Its object-oriented design maps naturally onto our extraction pipeline.
NetworkX: For graph manipulation and analysis, NetworkX has become the de facto standard in Python, providing algorithms for everything from centrality measurement to community detection.
PyVis: Interactive visualization transforms static networks into explorable landscapes. PyVis’s integration with web technologies enables the rich interactive features that make formal models accessible.
Pandas/NumPy: The workhorses of scientific Python handle data manipulation and numerical computation, providing the infrastructure on which everything else builds.
The integration challenge—making these tools play nicely together while maintaining performance and correctness—shaped many architectural decisions in AMTAIR. Each tool excels in its domain, but the seams between them required careful engineering.
The challenge of formalizing natural language arguments extends far beyond AI risk, touching on fundamental questions in logic, linguistics, and artificial intelligence.
Pollock’s work on cognitive carpentry Pollock (1995) provides philosophical grounding, arguing that human reasoning itself involves implicit formal structures that can be computationally modeled. This view—that formalization reveals rather than imposes structure—underlies AMTAIR’s approach.
Key theoretical challenges:
Recent work on causal structure learning from text Babakov et al. (2025) Ban et al. (2023) Bethard (2007) offers hope that these challenges can be addressed computationally. The convergence of large language models with formal methods creates new possibilities for bridging the semantic-symbolic gap.
One of the most persistent criticisms of Bayesian networks concerns their assumption of conditional independence given parents. In the real world, and especially in complex socio-technical systems like AI development, correlations abound.
Methods for handling these correlations have evolved considerably:
Copula Methods: By separating marginal distributions from dependence structure, copulas Nelson (2006) allow modeling of complex correlations while preserving the Bayesian network framework. Think of it as adding a correlation layer on top of the basic network.
Hierarchical Models: Introducing latent variables that influence multiple observed variables captures correlations naturally. If “AI research culture” influences both “capability progress” and “safety investment,” their correlation is explained.
Explicit Correlation Nodes: Sometimes the most straightforward approach is best—directly model correlation mechanisms as additional nodes in the network.
Sensitivity Bounds: When correlations remain uncertain, compute best and worst case scenarios. This reveals when independence assumptions critically affect conclusions versus when they’re harmless simplifications.
For AMTAIR, the pragmatic approach dominates: start with independence assumptions, identify where they matter through sensitivity analysis, then selectively add correlation modeling where it most affects conclusions.
The methodology of this research resembles less a linear march from hypothesis to conclusion and more an iterative dance between theory and implementation, vision and reality. Let me walk you through the choreography. Actually, that’s not quite right. It was messier than a dance. More like trying to build a bridge while crossing it, discovering halfway across that your blueprints assumed different gravity. The original plan seemed straightforward: take the MTAIR team’s manual approach, automate it with language models, validate against their results. Simple. Reality laughed at this simplicity. Language models hallucinate. Arguments don’t decompose cleanly. Probabilities hide in qualifying phrases that might mean 0.6 to one reader and 0.9 to another. Each solution spawned new problems in fractal recursion.
This research follows what methodologists might call a “design science” approach—we’re not just studying existing phenomena but creating new artifacts (the AMTAIR system) and evaluating their utility for solving practical problems (the coordination crisis in AI governance).
The overall flow:
This isn’t waterfall development where each phase completes before the next begins. Rather, insights from implementation fed back into theory, validation results shaped technical improvements, and application attempts revealed new requirements. The methodology itself embodied the iterative refinement it sought to enable.
The initial conception seemed straightforward enough. The MTAIR team had demonstrated that expert arguments about AI risk could be formalized into Bayesian networks. The process took hundreds of hours per model. Large language models had recently demonstrated remarkable capacity for understanding and generating structured text. The syllogism practically wrote itself: use LLMs to automate what MTAIR did manually. A few weeks of implementation, some validation, done.
That naive optimism lasted approximately until the first extraction attempt13. The LLM cheerfully produced what looked like a reasonable argument structure, except half the nodes were subtly wrong, several causal relationships pointed backward, and the probability estimates bore no discernible relationship to the source text. Worse, different runs produced different structures entirely. The gap between “looks plausible” and “actually correct” proved wider than anticipated.
What emerged from this initial failure was a recognition that the problem decomposed naturally into distinct challenges. Extracting structure—what relates to what—differed fundamentally from extracting probabilities. The former required understanding argumentative flow and causal language. The latter demanded interpreting uncertainty expressions and maintaining consistency across estimates. This insight led to the two-stage architecture that ultimately proved successful.
The development process resembled less a march toward a predetermined goal and more a conversation between ambition and reality. Each implementation attempt revealed new constraints. Each constraint suggested workarounds. Some workarounds opened unexpected possibilities. The final system bears only passing resemblance to the initial conception, yet it works—imperfectly, with clear limitations, but well enough to demonstrate feasibility.
The core methodological challenge—transforming natural language arguments into formal probabilistic models—requires careful consideration of what we’re actually trying to capture.
A “world model” in this context isn’t just any formal representation but specifically a causal model embodying beliefs about how different factors influence AI risk. The extraction approach must therefore:
Large language models enable this through sophisticated pattern recognition and reasoning capabilities, but they’re tools, not magic wands. The methodology must account for their strengths (recognizing implicit structure) and weaknesses (potential hallucination, inconsistency).
The journey from text to computation follows a carefully designed pipeline that mirrors human cognitive processes. Just as you wouldn’t ask someone to simultaneously parse grammar and solve equations, we separate structural understanding from quantitative reasoning.
The Two-Stage Process:
Stage 1 focuses on structure—what causes what? The LLM reads an argument much as a human would, identifying key claims and their relationships. The prompt design here is crucial, providing enough guidance to ensure consistent extraction while allowing flexibility for different argument styles.
Stage 2 adds quantities—how likely is each outcome? With structure established, the system generates targeted questions about probabilities. This separation enables different approaches to quantification: extracting explicit estimates from text, inferring from qualitative language, or even connecting to external prediction markets.
The magic happens in the interplay. Structure constrains what probabilities are needed. Probability requirements might reveal missing structural elements. The process is a dialogue between qualitative and quantitative understanding.
At the mathematical heart of Bayesian networks lie Directed Acyclic Graphs (DAGs)—structures that are simultaneously simple enough to analyze and rich enough to capture complex phenomena.
The “directed” part encodes causality or influence—edges have direction, flowing from cause to effect. The “acyclic” part ensures logical coherence—you can’t have A causing B causing C causing A, no matter how much certain political arguments might suggest otherwise.
Key properties for AI risk modeling:
Acyclicity: More than a mathematical convenience, this enforces coherent temporal or causal ordering. In AI risk arguments, this prevents circular reasoning where consequences justify premises that predict those same consequences.
D-separation: This graphical criterion determines conditional independence. If knowing about AI capabilities tells you nothing additional about risk given that you know deployment decisions, then capabilities and risk are d-separated given deployment.
Markov Condition: Each variable depends only on its parents, not on its entire ancestry. This locality assumption makes inference tractable and forces modelers to make intervention points explicit.
Path Analysis: Following paths through the graph reveals how influence propagates. Multiple paths between variables indicate redundancy—important for understanding intervention robustness.
The causal interpretation, following Pearl’s framework, transforms these mathematical objects into tools for counterfactual reasoning. When we ask “what if we prevented deployment of misaligned systems?” we’re performing surgery on the DAG, setting variables and propagating consequences.
Here we encounter one of the most philosophically fraught aspects of the methodology: turning words into numbers. When an expert writes “highly likely,” what probability should we assign? When they say “significant risk,” what distribution captures their belief?
The methodology embraces rather than elides this challenge:
Calibration Studies: Research on human probability expression shows systematic patterns. “Highly likely” typically maps to 0.8-0.9, “probable” to 0.6-0.8, though individual and cultural variation is substantial.
Extraction Strategies: The system uses multiple approximations:
Uncertainty Representation: Rather than false precision, we maintain uncertainty about probabilities themselves. This might seem like uncertainty piled on uncertainty, but it’s honest, helps avoid systematic biases—and mathematically tractable through hierarchical models.
The goal isn’t perfect extraction but useful extraction. If we can narrow “significant risk” from [0, 1] to [0.15, 0.45], we’ve added information even if we haven’t achieved precision.
Once we’ve built these formal models, we need to reason with them—and here computational complexity rears its exponential head. The number of probability calculations required for exact inference grows exponentially with network connectivity, quickly overwhelming even modern computers.
The methodology employs a portfolio of approaches:
Exact Methods: For smaller networks (<30 nodes), variable elimination and junction tree algorithms provide exact answers. These form the gold standard against which we validate approximate methods.
Sampling Approaches: Monte Carlo methods trade exactness for scalability. By simulating many possible worlds consistent with our probability model, we approximate the true distributions. The law of large numbers is our friend here.
Variational Methods: These turn inference into optimization—find the simplest distribution that approximates our true beliefs. Like finding the best polynomial approximation to a complex curve.
Hybrid Strategies: Different parts of the network might use different methods. Exact inference for critical subgraphs, approximation for peripheral components.
The choice of method affects not just computation time but the types of questions we can meaningfully ask. This creates a methodological feedback loop where feasible inference shapes model design.
While full integration remains future work, the methodology anticipates connection to live forecasting data as a critical enhancement. The vision is compelling: formal models grounded in collective intelligence, updating as new information emerges.
The planned approach would involve:
Semantic Matching: Model variables rarely align perfectly with forecast questions. “AI causes human extinction” might map to multiple specific forecasts about capabilities, deployment, and impacts. Developing robust matching algorithms is essential.
Temporal Alignment: Markets predict specific dates (“AGI by 2030”) while models consider scenarios (“given AGI development”). Bridging these requires careful probability conditioning.
Quality Weighting: Not all forecasts are created equal. Platform reputation, forecaster track records, and market depth all affect reliability. The methodology must account for this heterogeneity.
Update Scheduling: Real-time updates would overwhelm users and computation. The system needs intelligent policies about when model updates provide value.
Platforms like Metaculus Tetlock (2022) already demonstrate sophisticated conditional forecasting on AI topics. The challenge lies not in data availability but in meaningful integration that enhances rather than complicates decision-making.
With these theoretical foundations and methodological commitments established, we can now turn to the concrete implementation of AMTAIR. The next chapter demonstrates how these abstract principles translate into working software that addresses real governance challenges. The journey from theory to practice always involves surprises—some pleasant, others less so—but that’s what makes it interesting.
Multiple versions of Carlsmith’s paper exist with slight updates to probability estimates: Carlsmith (2021), Carlsmith (2022), Carlsmith (2024). We primarily reference the version used by the MTAIR team for their extraction. Extended discussion and expert probability estimates can be found on LessWrong.↩︎
Premise 1: APS Systems by 2070 \((P≈0.65)\) “By 2070, there will be AI systems with Advanced capability, Agentic planning, and Strategic awareness”—the conjunction of capabilities that could enable systematic pursuit of objectives in the world.↩︎
Premise 1: APS Systems by 2070 \((P≈0.65)\) “By 2070, there will be AI systems with Advanced capability, Agentic planning, and Strategic awareness”—the conjunction of capabilities that could enable systematic pursuit of objectives in the world.↩︎
Premise 2: Alignment Difficulty \((P≈0.40)\) “It will be harder to build aligned APS systems than misaligned systems that are still attractive to deploy”—capturing the challenge that safety may conflict with capability or efficiency.↩︎
Premise 3: Deployment Despite Misalignment \((P≈0.70)\) “Conditional on 1 and 2, we will deploy misaligned APS systems”—reflecting competitive pressures and limited coordination.↩︎
Premise 4: Power-Seeking Behavior \((P≈0.65)\) “Conditional on 1-3, misaligned APS systems will seek power in high-impact ways”—based on instrumental convergence arguments.↩︎
Premise 5: Disempowerment Success \((P≈0.40)\) “Conditional on 1-4, power-seeking will scale to permanent human disempowerment”—despite potential resistance and safeguards.↩︎
Premise 6: Existential Catastrophe \((P≈0.95)\) “Conditional on 1-5, this disempowerment constitutes existential catastrophe”—connecting power loss to permanent curtailment of human potential.↩︎
Overall Risk: Multiplying through the conditional chain yields $P(doom)≈0.05 $ or 5% by 2070.↩︎
This example, while simple, demonstrates all essential features of Bayesian networks and serves as the foundation for understanding more complex applications↩︎
These estimates include time for initial extraction, expert consultation, probability elicitation, validation, and refinement↩︎
For a comprehensive exploration of how this thesis could evolve into a full research program, see Appendix K: From Prototype to Platform. The technical challenges and methodological innovations required for scaling AMTAIR are detailed there, along with concrete pathways for community development.↩︎
If I’m honest about how this research actually developed, it looked nothing like the clean progression these methodology sections usually imply. The reality was messier, more iterative, occasionally frustrating, and ultimately more interesting than any linear narrative could capture.↩︎